Stories & Processes
Lessons from my Ambient Clinical Documentation System
In clinical AI systems we're navigating a hallucination minefield where one wrong output can trigger a litigation nightmare for a clinic. Today, in modern EHR's, you can't go without an AI-powered ambient clinical documentation system (ACDS), which has multiple layers that each carry their own error surface, that compound when orchestrated together.
HIPAA requirements really just got a second job.
Auditability used to be for auditors after the fact; now a clinician needs to see, in the moment, where the system pulled a claim from before they sign their name to it. PHI isolation and RBAC used to govern which humans could read what; now they also have to govern what the AI is allowed to read and write, too. HIPAA in any AI system got so much more important, and in my ACDS, that became very apparent.
What is an 'ambient clinical documentation system'?
An ACDS listens in on clinician-patient conversations and automatically takes notes based on transcripts--which a clinician edits and signs off on. This has shown to save considerable time and reduce burnout rate. I'd say it could--if it's fast enough.
These systems, though now common, are not trivial. And they're about to become even more difficult considering movement in tightening regulations in clinical AI systems.
How their typically built
Typically ACDS' look something like; some go for simpler alternatives; And hope the LLM will figure it out 🤞. Or today, you could even dare;
when using multi-modal models.
Compounding errors
In the first diagram, you can see four areas where hallucinations can originate; in audio (eg. noisy environments), transcribers (dealing with jargon, interruptions and mumbling), then the god-forsaken diarization (determining who said what)--infamously error-prone to this day. All this before the big boy LLM has their own hallucinations to contribute. All these layers add their own failure points that compound. It's almost surprising that these systems generate valuable insights in the first place!
The constraints not always addressed
Obviously, factuality is a huge need. The note produced by the system should be able to be scanned by a clinician and have them say 'yeah, that's what I would've written' -> signed. But a less addressed need is speed and latency. There were plenty of out-of-the-box solutions for medical note-taking, but the biggest reason why the client didn't want to use them was that they could write the note faster than the AI could produce. They'd rather write it themselves than wait. On top of that, as some existing POC's were getting tested, some math I did showed cost was going to be an issue quickly as it scaled.
How I built mine
The requirements were clear; make sure the output is ironclad and produced fast--bonus points for cost-efficiency. The 'fast' requirement meant we can't just go for the simple 'dump the entire transcript into an LLM when they're done' approach, we're going to have to build these notes on-the-fly. Ideally having them be compiled and reviewable as they're speaking.
To do this, I added a realtime graph-RAG layer using LightRAG. Incoming transcript chunks would incrementally build a knowledge graph that can then be used by LLM's for context. The nodes of the graph became people, events, objects, things. And the edges were how they related to each other. Furthermore, it stores which chunks support a certain node or edge, giving greater capability to audit and trace back which part of a session contributed to the note.
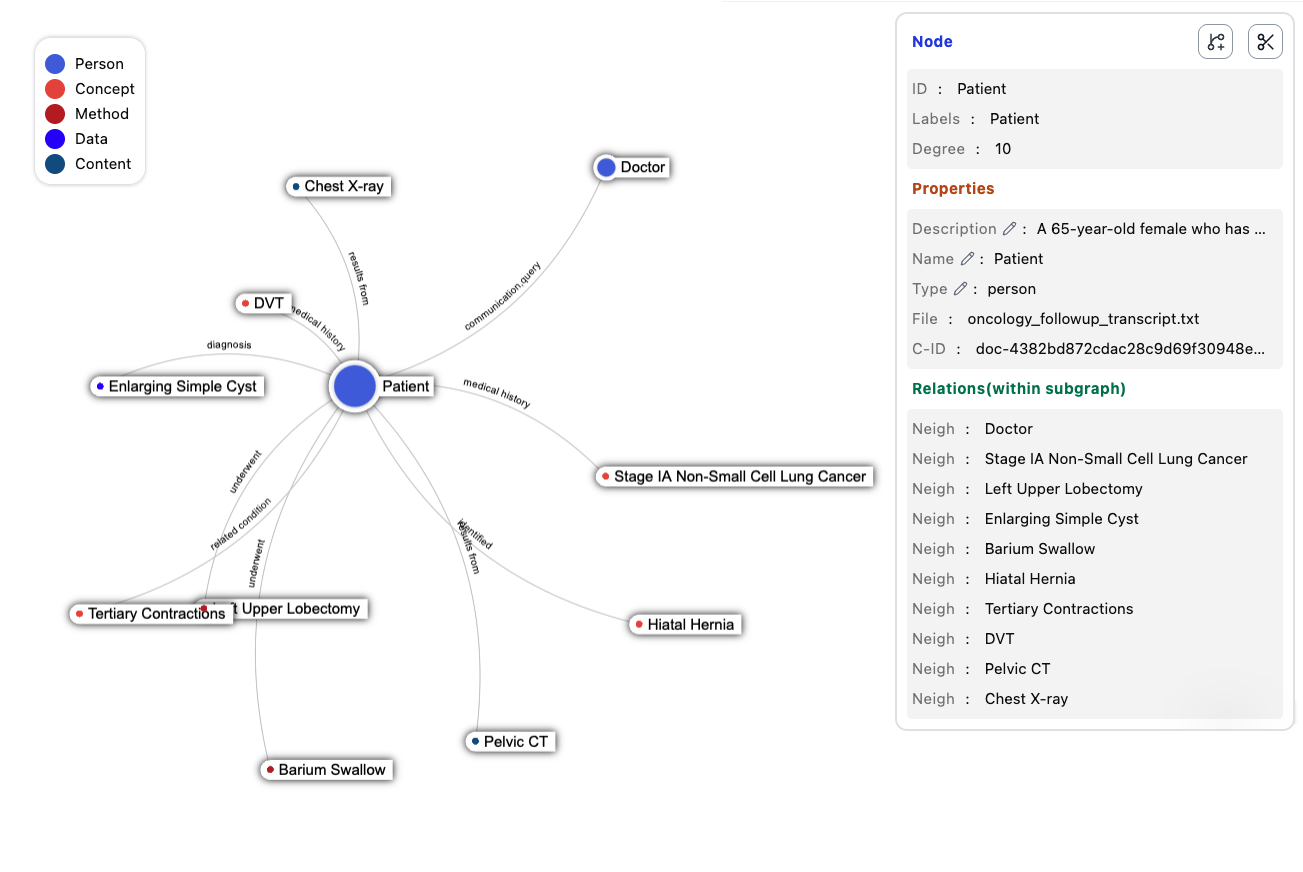
This does a couple things;
- Data incremented into useful information, in realtime.
- Small/cheap LLM's can be used to build the graph.
- Traceability: each chunk of information gets tracked, making auditability much easier later.
This feature can easily go beyond ACDS. Keep and merge these graphs into one patient knowledge base for clinicians to explore.
Risks I would need to look into further;
- It does not address the hallucination risks. At best, it might lower LLM hallucination.
- It could be a lossy process where certain nuances or changes to a story could fail to propagate.
Conclusion
The concept had real potential and I'd build it again. Exploring a patient's data through a graph has some real exciting potential too. But I'd choose the foundation differently. Getting a summary out of a transcript is trivial with LLM's. It's the PHI isolation, access control, traceability, auditability in a live clinician-facing feature that simply can't be parsed in after. Build for those on day one--or do what I did and hack them into a foundation that you find out won't hold them.